The xlwSciPy spreadsheet (last presented here) has been updated for the latest version of xlwings and Scipy.
The new spreadsheet can be downloaded from:
xlScipy-xlw.zip
including full open source code.
The spreadsheet requires Python, including xlwings, Numpy, Scipy and Pandas (all of which are free, and included in the Anaconda package).
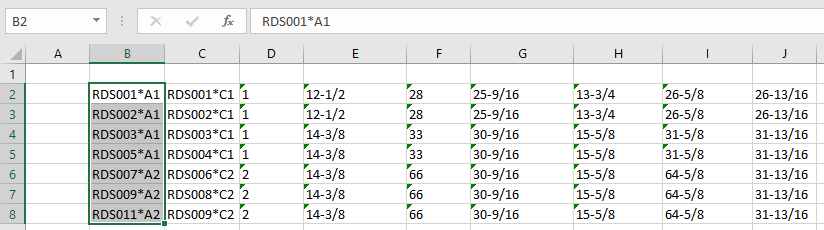
The new spreadsheet includes a CubicSpline function, which is new in Scipy 0.18. Some options for the new function are shown in the screen shots below:
The function has an optional “BC-type” argument, that controls the spline end conditions. The argument may be entered as a single text string (one of: “not-a-knot”, “periodic”, “clamped”, or “natural”), or a 2×2 array. The default value is “not-a-knot”, which returns the same results as the xl_UniSpline and xl_Splev functions: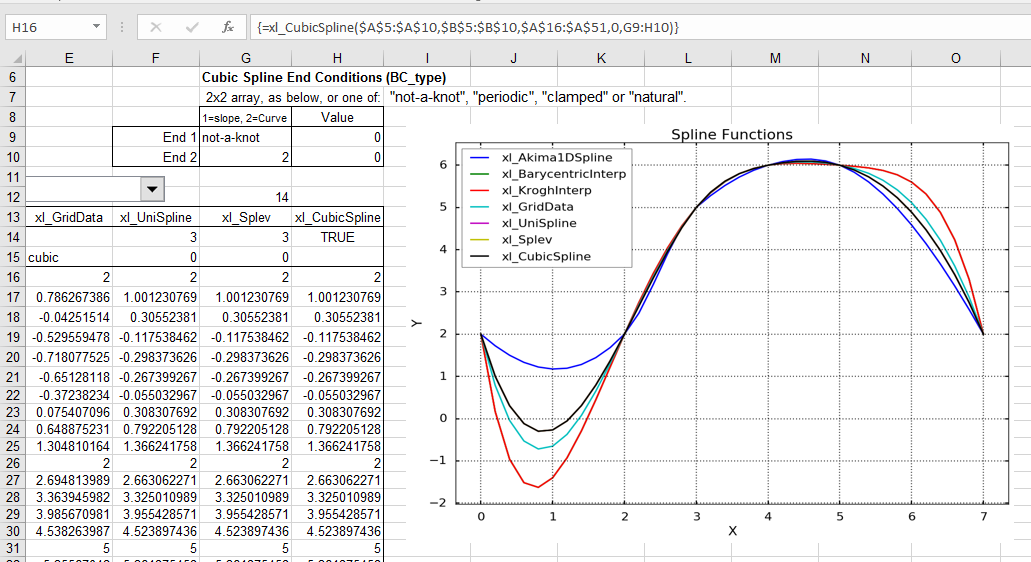
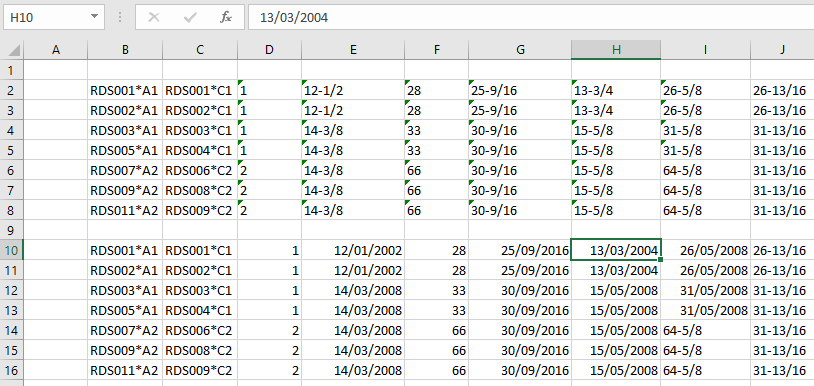
For the “periodic” option the first and last Y value in the spline data must be equal. The function then returns a curve with equal slope and curvature at each end:
“Clamped” end conditions result in zero slope at the ends:
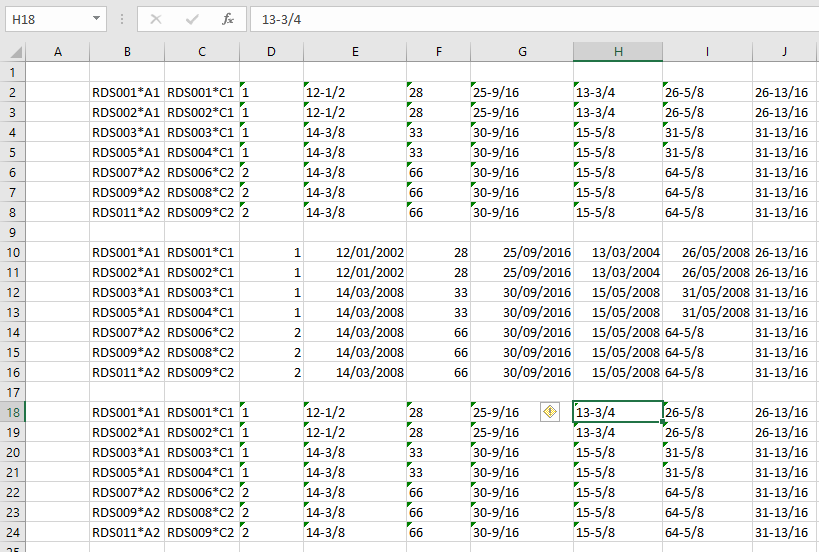
“Natural” end conditions have zero curvature at the ends: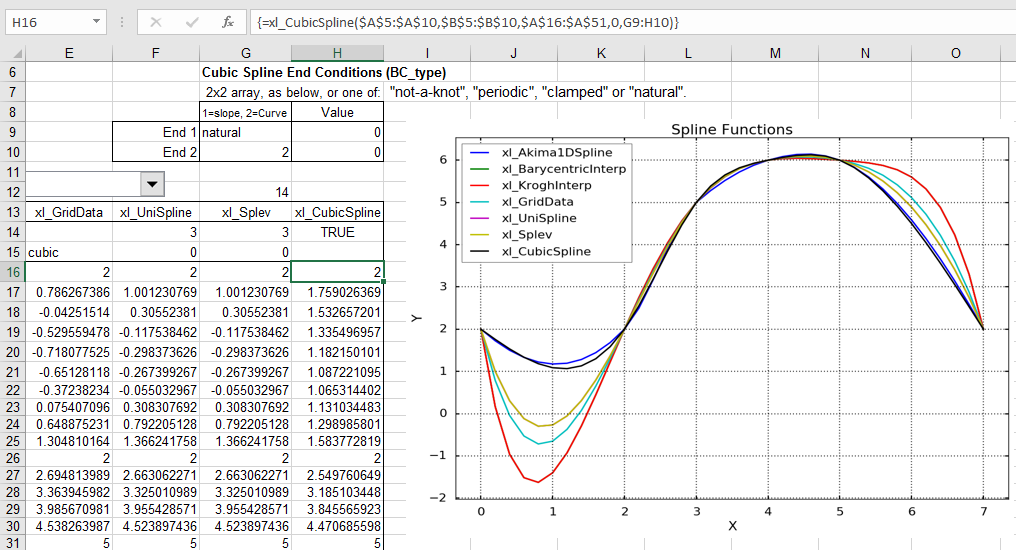
Using the array argument the slope or curvature may be set separately at each end. The input shown below specifies a slope (1 in column 1) of -1 at both ends: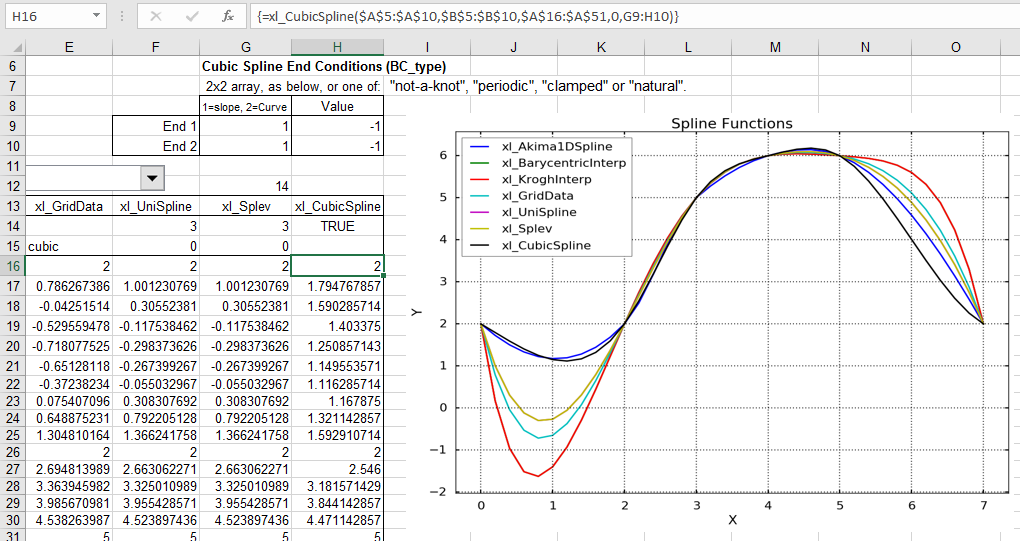
Similarly the curvature may be set to any desired value with a 2 in column 1 of the BC_type array: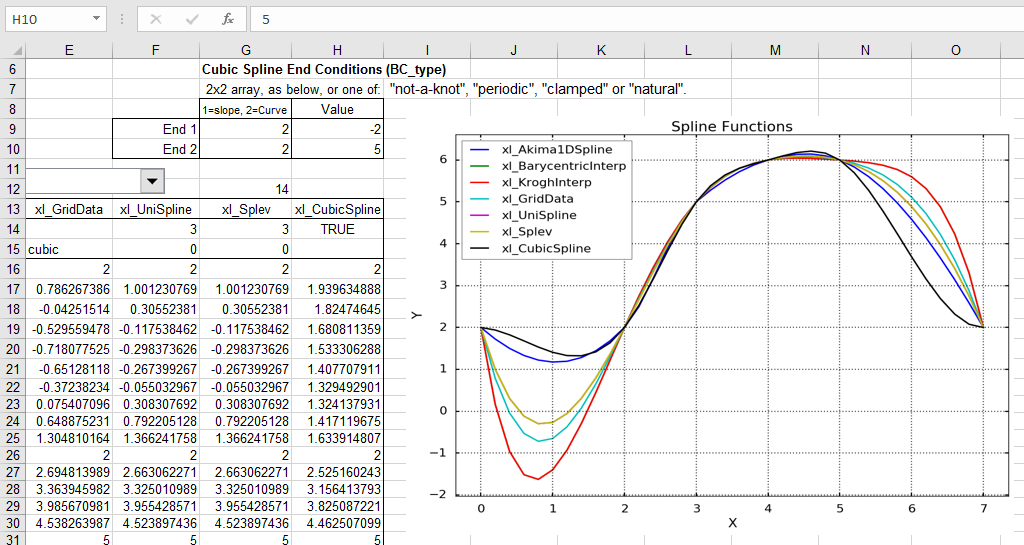
See more detailed documentation at the Scipy Docs.
Xlwings 0.10 introduces a new feature that expands array return values in user defined functions (UDFs) to show all the results, without entering as an array function: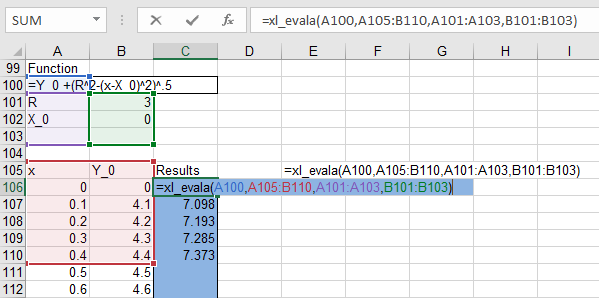
This feature is currently only used in the xl_evala function, on the Eval sheet. Xl_evala returns an array with the same number of rows as the rows with numeric data in the input data. When entered with the data from row 106 to 110 in the screen shot above, results are automatically returned to the same rows when the functioned is entered (just press enter, not ctrl-shift enter).
If the input range is extended down to row 136, the output is adjusted to suit: 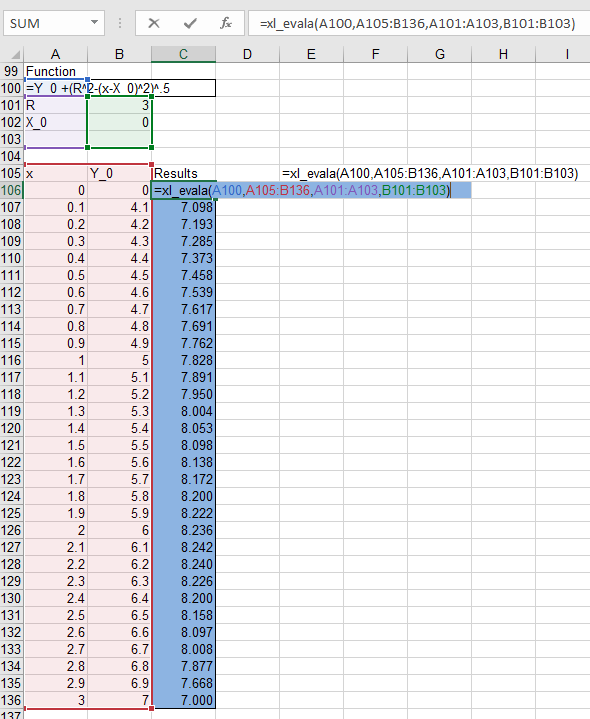
The Python code required is quite short:
@xw.func
@xw.arg("x", ndim=2)
@xw.ret(expand='table')
def rtnarray2(x):
return x
This can then be called from VBA …:
Function rtnarray2(x)
If TypeOf Application.Caller Is Range Then On Error GoTo failed
rtnarray2 = Py.CallUDF("xlwScipy", "rtnarray2", Array(x), ThisWorkbook, Application.Caller)
Exit Function
failed:
rtnarray2 = Err.Description
End Function
… and tacked on the end of any other VBA function:
Function xl_EvalA(func As String, xRange As Variant, Optional SymRange As Variant, Optional ValRange As Variant, Optional ReturnType As Long = 1) As Variant
...
Set result = Py.Call(Methods, "xl_Evalx", Py.Tuple(func, xRange, VarName, SymRange, ValRange))
Set Result_List = Py.Call(result, "tolist")
Rtn = Py.Var(Result_List)
Rtn = TransposeA(Rtn)
xl_EvalA = rtnarray2(Rtn)
Exit Function