… is a new book by Mark Gardener, published by Pelagic Publishing.*
It is subtitled “Organising, summarising and visualising scientific data”. The publishers say of the book:
Microsoft Excel is a powerful tool that can transform the way you use data. This book explains in comprehensive and user-friendly detail how to manage, make sense of, explore and share data, giving scientists at all levels the skills they need to maximize the usefulness of their data.
Readers will learn how to use Excel to:
* Build a dataset – how to handle variables and notes, rearrangements and edits to data.
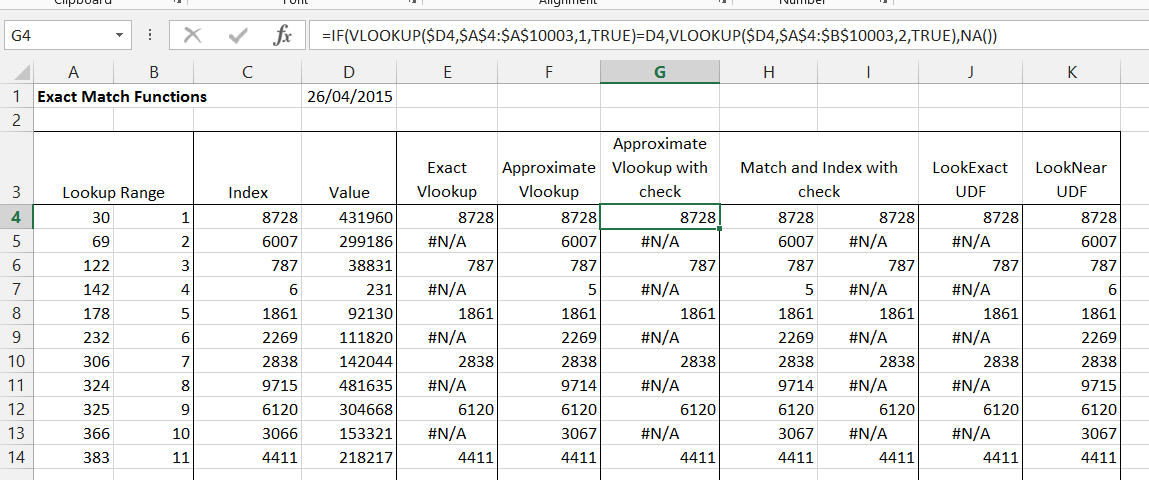
* Check datasets – dealing with typographic errors, data validation and numerical errors.
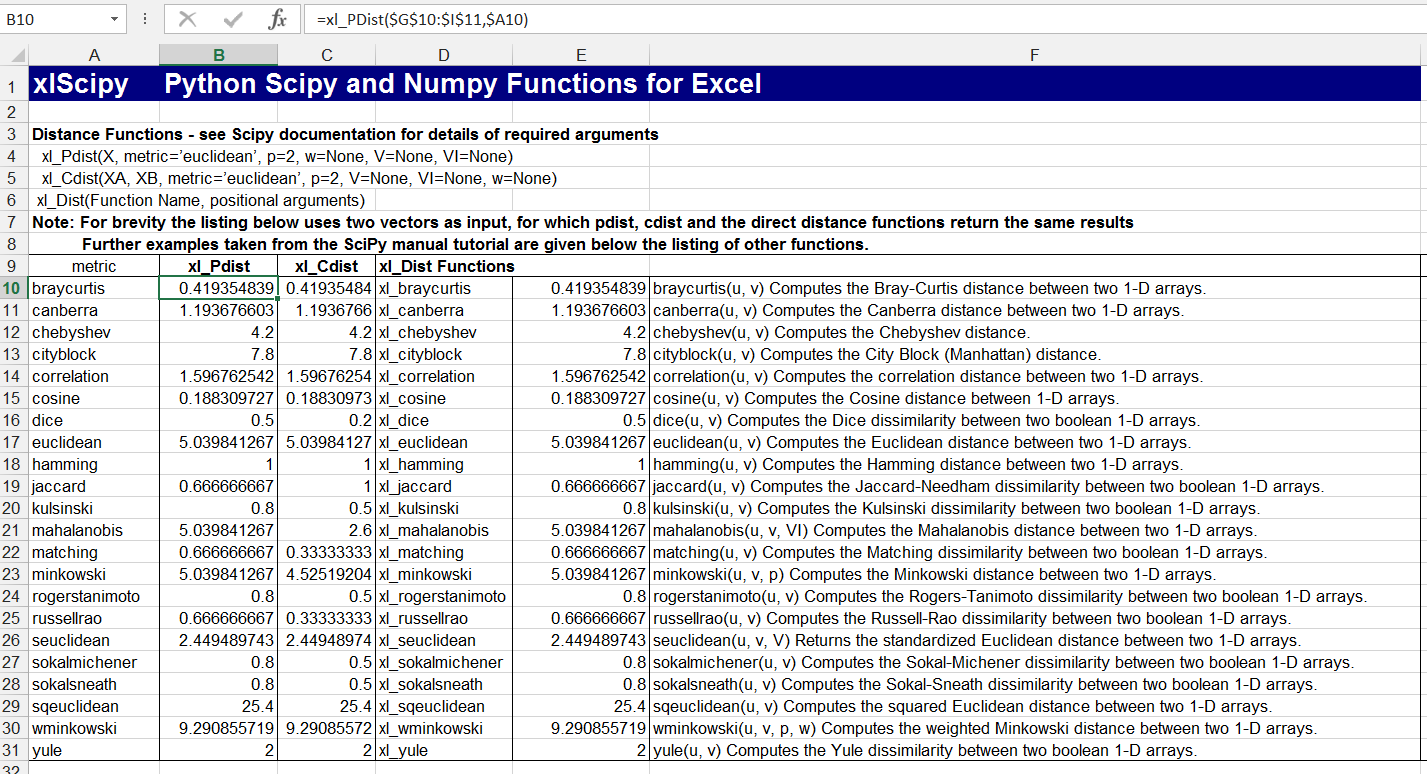
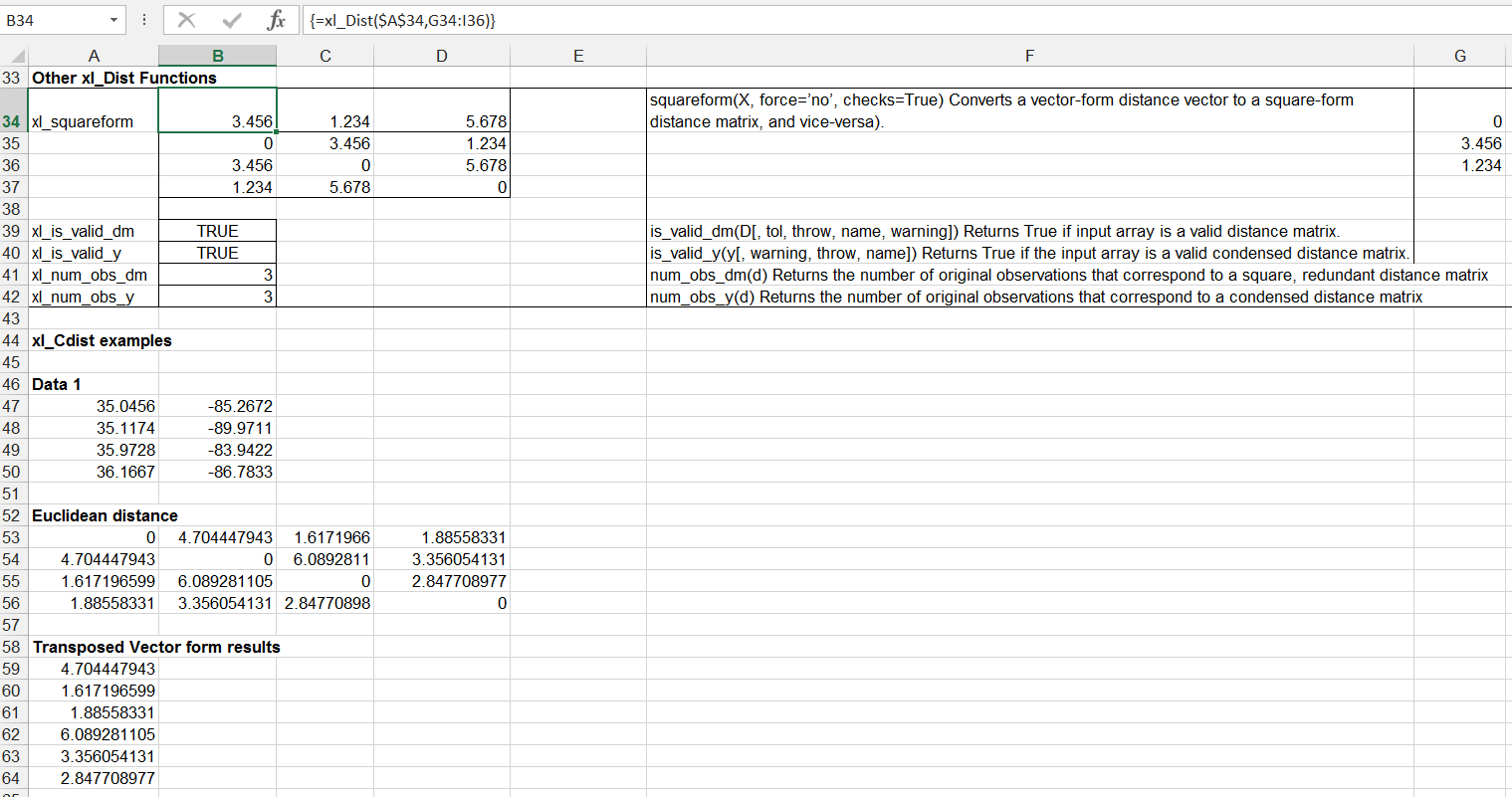
* Make sense of data – including datasets for regression and correlation; summarizing data with averages and variability; and visualizing data with graphs, pivot charts and sparklines.
* Explore regression data – finding, highlighting and visualizing correlations.
* Explore time-related data – using pivot tables, sparklines and line plots.
* Explore association data – creating and visualizing contingency tables.
* Explore differences – pivot tables and data visualizations including box-whisker plots.
* Share data – methods for exporting and sharing your datasets, summaries and graphs.Alongside the text, Have a Go exercises, Tips and Notes give readers practical experience and highlight important points, and helpful self-assessment exercises and summary tables can be found at the end of each chapter. Supplementary material can also be downloaded on the companion website.
Managing Data Using Excel is an essential book for all scientists and students who use data and are seeking to manage data more effectively. It is aimed at scientists at all levels but it is especially useful for university-level research, from undergraduates to postdoctoral researchers.
Clearly the book is aimed at scientists, particularly those dealing with the analysis of observational data, but is it of value to a wider audience? Having worked through the book I would say that it is definitely worthwhile for many other groups, including those in engineering and other branches of science and technology, and also those in commercial and marketing work dealing with the analysis of numerical data of any kind.
Aspects of the book that I found particularly useful were:
- Detailed and clear descriptions of the use of pivot tables in the analysis and summary of numerical data of any kind (an area where I could certainly make more use of the features available in Excel)
- Clearly laid out procedures for arranging, checking and exploring data.
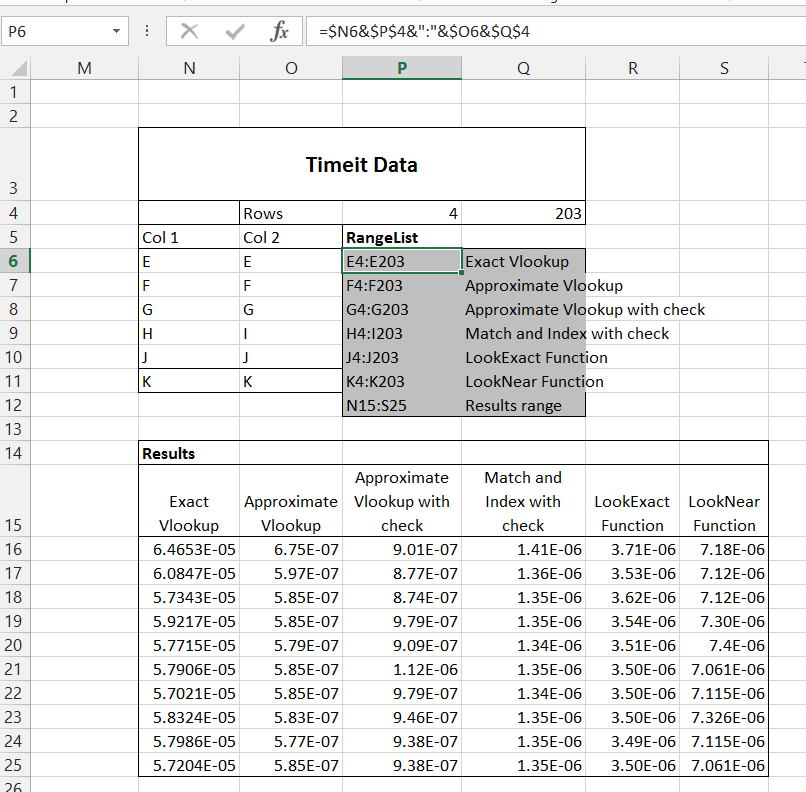
- Detailed procedures for display of data in a wide variety of graphs.
- Detailed step-by step example spreadsheets available from the publisher’s web-site.
This is certainly not a book “for dummies”, and some may find the emphasis on scientific procedures off-putting, but for those willing to spend some time working through the examples I believe it will be of value to anyone who uses Excel to organise, summarise and visualise numerical data of any kind.
* Pelagic Publishing provided me with a free copy of the book for this review; I have no other connection with the publishers or the author.